
Fast, accurate, and scalable search results are made possible by RAG Pipelines, which have completely changed search systems. Nevertheless, many RAG Pipelines are unable to operate at peak efficiency, despite their potential. A number of typical constraints that might impair pipeline performance include insufficient resource allocation, improper query optimization, and inefficient data feeding.
We'll examine the most frequent obstacles preventing your RAG pipeline from operating effectively in this post, along with workable solutions. Through the identification and resolution of these bottlenecks, you can fully realize the potential of your RAG Pipeline and provide outstanding search experiences.
Understanding RAG Pipelines
AI-driven content production and data analysis are being revolutionized by retrieval-augmented generation (RAG) pipelines. Information retrieval and text generation are the two essential tasks of natural language processing (NLP) that are combined in RAG. To improve the relevance and accuracy of generated outputs, RAG pipelines include external information retrieval, in contrast to classic generative models that only use internal knowledge to produce content.
Common Bottlenecks in RAG Pipelines
When it comes to RAG Pipelines, I believe that bottlenecks can arise from a multitude of factors, ultimately hindering the pipeline's performance and scalability. In my opinion, three common bottlenecks that can significantly impact pipeline efficiency are inefficient data ingestion, suboptimal query optimization, and inadequate resource allocation.
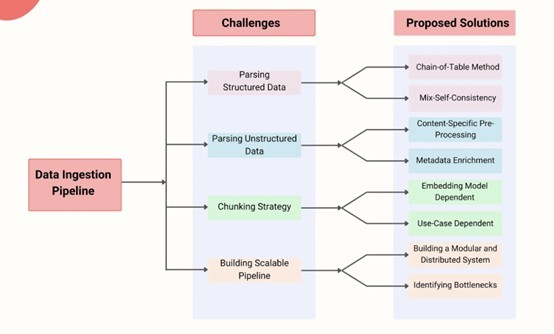
Inefficient Data Ingestion
Inefficient data ingestion can lead to slow data processing rates, high latency, and even data loss. This bottleneck often stems from inadequate data processing algorithms, poor data quality, and insufficient resources. I think that the root cause of this bottleneck lies in the inability of traditional data processing techniques to handle the sheer volume and velocity of modern data. As a result, data ingestion becomes a chokepoint, slowing down the entire pipeline.
Suboptimal Query Optimization
Suboptimal query optimization is another common bottleneck that can significantly impact pipeline performance. When queries are not optimized, they can lead to slow response times, high CPU usage, and poor search relevance. In my experience, this bottleneck often arises from inadequate indexing strategies, inefficient ranking algorithms, and poor query rewriting techniques. I believe that the key to overcoming this bottleneck lies in adopting advanced query optimization techniques, such as machine learning-based ranking models and column-store indexing.
Inadequate Resource
Lastly, inadequate resource allocation can lead to resource starvation, slow pipeline execution, and poor scalability. This bottleneck often stems from insufficient resources, poor resource allocation, and inadequate monitoring. I think that the solution to this bottleneck lies in adopting dynamic resource allocation strategies, scaling resources to match pipeline demands, and implementing robust monitoring and profiling tools. By addressing these common bottlenecks, developers can significantly improve the performance, scalability, and efficiency of their RAG Pipelines.
Best Practices for RAG Pipeline Optimization
To overcome the common bottlenecks and ensure optimal performance, scalability, and efficiency, I believe that adhering to best practices is crucial. In my opinion, one of the most critical best practices is to design a modular and scalable architecture that can handle increasing data volumes and query loads. This can be achieved by adopting a microservices-based architecture, where each component is designed to scale independently.
Additionally, implementing a robust data ingestion framework that can handle high-volume and high-velocity data is essential. This can be achieved by leveraging distributed data processing frameworks, such as Apache Spark or Apache Flink, and adopting data streaming technologies, such as Apache Kafka or Amazon Kinesis.
Conclusion
In conclusion, RAG Pipelines are a critical component of modern search systems, enabling fast and relevant search results. However, they can be prone to bottlenecks that impact performance, scalability, and efficiency. By understanding the common bottlenecks and adopting best practices, developers can optimize their RAG Pipelines for exceptional search experiences. I believe that leveraging innovative technologies, such as Vectorize.io, can further accelerate pipeline performance and scalability.
By integrating Vectorize.io into their RAG Pipelines, developers can unlock new levels of performance and efficiency, ultimately delivering exceptional search experiences to users. By following these guidelines and leveraging cutting-edge technologies, developers can build high-performance RAG Pipelines that meet the demands of modern search applications.
What's your reaction?








You may also like
-

Bitcoin Boom Incoming?
-
How to Choose the Right Pharma SFA Software for Your Company
-
Nano Banana Pro Changes How Image Quality Gets Judged
-
Repair First, Replace Later: The Smarter Way to Keep Laptops Running in 2026
-
How to Customize Your WooCommerce My Account Page for Better User Experience
-
AutoScience AI Builds AI Models: Recursive Intelligence












Comments
0 comment